Exkurs - Hierarchien speichern

Es ist recht schwierig SQL-Anfragen zu schreiben, die die Hierarchie in mehreren Stufen durchlaufen sollen.
Beispiel
 Herr Winkelmann will wissen, welche Benutzer von seinen angeworbenen Benutzern eingeladen
wurden (sozusagen die "Enkel" in der Werber-Hierarchie). Dies leistet der folgende SQL-Befehl
(das Ergebnis siehst du rechts):
Herr Winkelmann will wissen, welche Benutzer von seinen angeworbenen Benutzern eingeladen
wurden (sozusagen die "Enkel" in der Werber-Hierarchie). Dies leistet der folgende SQL-Befehl
(das Ergebnis siehst du rechts):
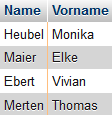
SELECT enkel.Name, enkel.Vorname
FROM benutzer AS opa, benutzer AS kind, benutzer AS enkel
WHERE opa.Name = 'Winkelmann' AND opa.Vorname = 'Paul'
AND opa.PNR = kind.WerberPNR
AND kind.PNR = enkel.WerberPNR
Wie kann man aber jetzt alle indirekt geworbenen Benutzer von Herrn Winkelmann finden? In einem SQL-Befehl ist dies nicht möglich (zumindest mit "Standard"-SQL). Eine neue Tabelle kann hier Abhilfe schaffen:
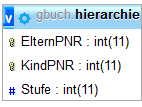 Die
Die hierarchie-Tabelle speichert alle Beziehungen eines Knotens (auch die indirekten) ab. Als
zusätzliche Information wird die "Entfernung" vom Elternknoten abgelegt.
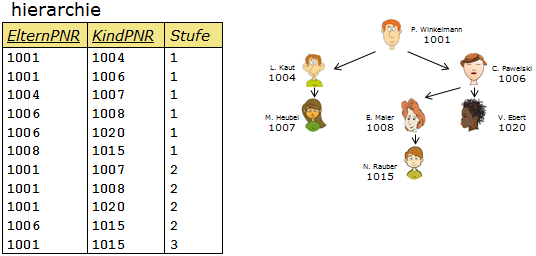
- Ausgangssituation.
- Erste Stufe.
- Zweite Stufe.
- Dritte Stufe.
 Klicke auf die einzelnen Schritte zur Veranschaulichung.
Klicke auf die einzelnen Schritte zur Veranschaulichung.
Vorteil der Struktur ist die Vereinfachung der Abfragen - Nachteil sind die redundant hinterlegten Informationen, was leicht zu Fehlern führen kann. Dieses Dilemma findest du häufig in Datenbanken:
Redundante (mehrfache) Speicherung der gleichen Informationen kann Anfragen erleichtern - dafür ist es möglich, unter Umständen inkonsistente (nicht passende) Daten zu speichern.
Ein Ausweg daraus stellt die automatische Änderung der Hierarchietabelle durch das Datenbanksystem dar, was mit dem Konzept der sog. Trigger möglich ist. Dies wird hier aber nicht weiter verfolgt.
Für Experten...
Vielleicht interessiert dich ja, wie die Hierarchietabelle erzeugt wurde. Die SQL-Befehle kannst du hier nachlesen: SQL-Befehle zum Erzeugen der Hierarchie-Tabelle
Quellen
-
[1]: Hierarchie von Benutzern - Urheber: TM - Lizenz: inf-schule.de
unter Verwendung von:
- Verschiedene Icons - Urheber: knollbaco - Lizenz: Public Domain
