Exkurs - Aufwand bei der Spracherkennung
Lange Wartezeiten
Grammatiken und reguläre Ausdrücke dienen zur Beschreibung von Sprachen. Sie sind nicht auf schnelle Spracherkennung optimiert. Das zeigt sich, wenn man Experimente mit JFlap durchführt.
Betrachte noch einmal die Grammatik für vereinfachte E-Mail-Adressen.
E -> U@D U -> N D -> ST S -> N. S -> N.S T -> bb N -> B N -> BN B -> b
Wenn man diese Grammatik in JFlap eingegeben hat,
dann kann man mit den Menupunkten [Input] und [Brute Force Parse] Spracherkennung bei vorgegebenen Wörtern
vornehmen.
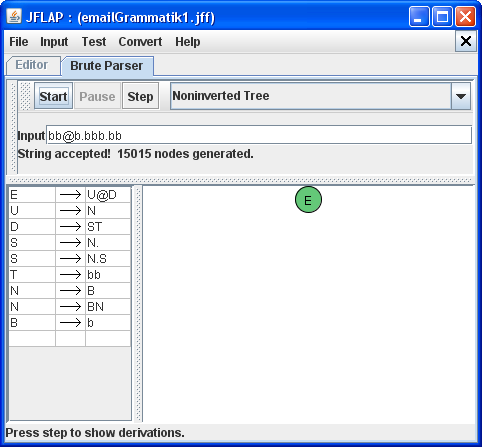
Gib hierzu in das [Input]-Feld eine zu analysierende Zeichenfolge ein, z.B. bb@b.bbb.bb.
Mit dem Menupunkt [Start] wird jetzt die Suche nach einer Ableitung des eingegebenen Wortes mit Hilfe
der vorgegebenen Ersetzungsregeln gestartet. Achtung, diese Suche kann eine Weile dauern.
Wenn sie erfolgreich beendet wird, dann erhält man folgende Rückmeldung:
Aufgabe 1
Probiere das selbst einmal aus. Warum dauert es so lange, bis JFlap ein Ergebnis liefert? Hast du eine Erklärung für das Verhalten?
Schnelle Rückmeldungen
Wenn man einen deterministischen endlichen Automaten zur Spracherkennung benutzt, dann erhält man ohne Wartezeiten direkt eine Rückmeldung.

Aufgabe 2
Probiere das selbst einmal aus. Warum kann man mit einem deterministischen Automaten schnell ein Wort auf Zugehörigkeit zu einer Sprache überprüfen? Wird das bei nichtdeterministischen Automaten genauso schnell erfolgen?